Pandas
- Pandas是Python中的一個資料處理套件,主要有兩種資料結構:
- Series
- Data Frame
Series
- Series是一維資料陣列,類似array或list
- 要使用Pandas,需先import pandas。
- 因為常與numpy合用,所以也需要import numpy。
- 使用pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)來建立。最主要的data可以是list, tuple, ndarray等。index預設值為由0開始之整數。
- Dictionary與Series非常契合,可以直接轉換。
- 類似一個array,但是有顯示index。
- 欲取得其中資料,可使用類似array的方法,e.g. s1[0], s1[-1], s2[1], s2['c'], s2[['a','e']], s2[s2>3]。
pandas1.py
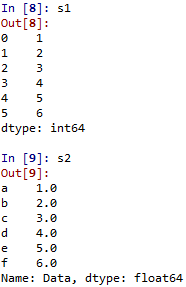
- Series的屬性:
- s2.axes。
- s2.dtype or s2.dtypes。
- s1.hasnans。
- s1.empty: 查看是否為空。
- s2.iloc[[0,1,2]], s2.iloc[np.arange(3)], s2.iloc[3:6] or s2.iloc[[True, False, True, True, False, True]]。
- 省略iloc依然可得到相同結果,e.g. s2[np.arange(3)], s2[list(range(0,6,2))]
- s2.loc['b'], s2.loc['b':]。
- iloc的index參數僅可用數字,所以s2.iloc['b']是錯的。loc的index參數僅可用index名稱,所以在此s2.loc[2:]是錯的。
- s1.iloc[:3]的意思是取前三個,而s1.loc[:3]的意思取到index為3止。
- s2.index: 等同s2.keys()。
- s2.is_monotonic, s2.is_monotonic_decreasing, s2.is_monotonic_increasing。
- s2.is_unique: 如果data內有重複資料則傳回false。
- s2.itemsize: s2.dtype/8。
- s2.nbytes: s2.itemsize*s2.size。
- s2.ndim。
- s2.shape。
- s2.size。
- s2.values: Return Series as ndarray or ndarray-like depending on the dtype。
- 上述屬性原則上多能用在DataFrame
Operations
- Series原則上與list, tuple, ndarray等類似,也能進行大部分運算。
- 改變其中的值: s1[0] = 100。
- 改變數值型態: s1.astype('float')。
- 基本運算(+,-,*,/,**,//,%): s1**2, s1/3。
- 若要進行s1+s2(s1.add(s2)),兩者的index相同者才會相加(e.g. s2+s3),index不同處則疊加。
- 若要疊加直接使用append >> s1.append(s2)。
- s2.combine(s3, lambda i, j: i if i==j else 0):combine兩個Series,函數須給兩參數,然後傳回一個傳回值。
- 數學函數: np.sin(s1),np.log(s1), np.sqrt(s1)。
- 使用agg(aggregate)將函數應用於Series上: s1.agg('min')或s1.agg(lambda x: x+2)或s1.agg(['min', 'max'])。
- 也可以使用apply: s1.apply(lambda x: x+2),s1.apply('sqrt'), s1.apply(['min','max'])。
- 也可以使用transform: s1.transform(lambda x:x+2)或s1.transform(lambda x:np.sqrt(x))。
- 或使用pipe: s1.pipe(np.min)或s1.pipe(min)或s1.pipe(np.sin)。
- s2.add(s3), s2.sub(s3),s2.mul(s3),s2.div(s3): s2+-*/s3(subtract, multiply, divide)。
- s1.mod(3): s1%3。
- s2.pow(s3): s2的s3次方。
- s2.prod()(或s2.product()): production of s2。
- s9 = pd.Series(np.random.rand(10)) >> s9.round(2): 取小數後2位四捨五入。
- 統計相關函數:
- s1.describe()。
- s1.count()。
- s1.max()。
- s1.min()。
- s1.mean()。
- s1.median()。
- corr(other, method='pearson', min_periods=None): correlation with `other` Series, excluding missing values。s1.corr(s5)或s1.corr(s5, 'pearson')或s1.corr(s5, 'kendall')。
- cov(other, min_periods=None):covariance with Series, excluding missing values。s1.cov(s5)
- diff(periods=1): discrete difference of object。
- s1.pct_change(): 前後元素的增減比例。
- mad(axis=None, skipna=None, level=None): mean absolute deviation。
- s5.std(): standard deviation。
- s2.ptp():最大跟最小值之差。
- s1.sample(3) or s1.sample(n=3): 隨機取三個元素。
- s5.sem(): unbiased standard error of the mean。
- s5.sum()。
- s5.var(): unbiased variance。
- 邏輯判斷: 判斷是否符合條件。
- s1>3: 傳回一個boolean陣列。若是s1[s1>3]則傳回符合條件(True)的Series。
- s1.clip(2,5),s1.clip_lower(2),s1.clip_upper(5): 將小於2的值變成2,大於5的值變成5。
- s1.isin(array): s1.isin([2,5]),傳回一個boolean陣列(值為2或5傳回True)。若是s1[s1.isin[2,5]]則傳回符合條件(True)的Series。
- s1.isnull(): 判斷是否為missing values(e.g. np.NaN)。
- s1.notnull(): 判斷是否不為missing values。
- all() & any(): Series.all(axis=0, bool_only=None, skipna=True, level=None, **kwargs)
- duplicated(keep='first'): 判斷是否有重複。keep='first'表示判斷該元素之前是否有與其重複之元素,keep = 'last'表示判斷該元素之後是否有與其重複之元素,keep = False表示判斷該元素是否為重複元素。
- s2.eq(s3): 判斷對應元素是否相等。
- s2.ge(s3): 判斷對應元素是否大於等於。
- s2.gt(s3): 判斷對應元素是否大於。
- s2.le(s3): 判斷對應元素是否小於等於。
- s2.lt(s3): 判斷對應元素是否小於。
- s2.ne(s3): 判斷對應元素是否不等於。
- s1.idxmax(): 傳回最大值之index。
- s1.idxmin(): 傳回最小值之index。
- s1.items() or s1.iteritems(): 傳回項目的iterable物件。
- s.last_valid_index(): Return index for last non-NA/null value.。
- s1.where(s>3) vs. s1.mask(s>3): where保留True處理False,mask保留False處理True。s1.where(s1>3,100) vs. s1.mask(s1>3, 100)。
- s.nunique(): 判斷非重複的元素個數。
- s.unique(): 傳回沒有重複元素的array。
- 選取或處理元素: 選取Series內之元素。
- s1.get(2): 相當於s1[2] or s1.at[2]。
- s1.get_values(): 相當於s1.values。
- s1.get_dtype_counts(): 判斷各類型元素個數。
- s1.compress(s1>3): 等同s1[s1>3]。
- s1.between(2,5) & s1[s1.between(2,5)]: s1.between(2,5, inclusive=False)不包含判斷值。也可用於字串e.g. between('c','k')。
- s1.copy(): 建立物件的copy。
- s1.pop(0): 移除index為0之元素。
- s1.drop(3): 刪除index為3之元素。
- s1.drop_duplicates(): 刪除重複元件。
- s1.dropna(): 刪除missing values。
- groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs): s1.groupby(lambda x: x>3).mean()。
- s1.head(3): 選取前三元素。
- s1.tail(3): 選取後三元素。
- s2.map(s1): s1的值對應至s2或function應用到s2。
- s5.nlargest(5): 選擇前五大的值。
- s5.nsmallest(5): 選擇前五小的值。
- s.nonzero(): 選擇值非0的index。
- s2.reindex_like(s3): 使用s3的index,s2的值。
- s1.repeat(3): 重複元素3次。
- s1.replace(1,100): 將s1中的值為1替換成100。
- s1.rolling(2).sum(): 每2個元素之和,傳回Series。
- s1.sample(3) or s1.sample(n=3): 隨機取三個元素。
- s1.take([1,3]): 選取index=1,3的元素,自0起算。
- s.update(pd.Series([1,2,3,4,5])): 更新s內的元素值。
- s.unique(): 傳回沒有重複元素的array。
- indexing:
- s1.add_prefix('item_')或s1.add_suffix('_item')。
- s1.reindex([1,3,5,2,'d','e'])。
- s1.rename(lambda x: x**2), s1.rename('demand'), s1.rename({0: 100, 1: 200})。
- s1.rename_axis('customers')or s1.rename_axis('customer', axis= 0): change axis in DataFrame。
- s1.set_axis(0, ['a', 'b', 'c','d','e','f']): 將s1的index改為第二個參數。
- unstack(level=-1, fill_value=None):用來將多重index轉換成DataFrame。
- s.value_counts(): 計算各元素個數。
- 內插(interpolate):
- 排序:
- s7.argsort()傳回index的排序(非元素值的排序)。
- s8.sort_index()傳回一個Series,此Series根據index排序。
- 若使用s8.sort_index(ascending=False)>>降冪。
- 若使用s8.sort_index(inplace=True)>>直接排序s8(不需再指派給其他變數)。
- 若包含NaN且想將其排在上方,則使用s8.sort_index(na_position='first')。
- s8.sort_values()傳回一個Series,此Series根據value排序。
- 若使用s8.sort_values(ascending=False)>>降冪。
- 若使用s8.sort_values(inplace=True)>>直接排序s8(不需再指派給其他變數)。
- 若包含NaN且想將其排在上方,則使用s8.sort_values(na_position='first')。
- 資料處理傳輸
- s5.to_clipboard(): 複製到system clipboard。
- s1.to_csv('temp.csv'): 寫到csv檔。
- s1.to_dict(): 轉為dict。
- s1.to_excel("data.xls",'Sheet1'): 寫到excel檔。
- s1.to_frame(): 轉換為dataframe。
- s5.to_json(): 轉換為JSON。
- s1.to_string()。
- s5.tolist(): 傳回values的list。
pandas1.py
DataFrame
- DataFrame是多維陣列,原則上就是多個Series的組合,建立方式可為如下方式:
- pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)。
- 使用dict來建立,每一個column為一個Series。
- 使用index參數來改變index名稱(row),使用columns來改變column名稱。
- 原則上Series的參數屬性多可用在DataFrame,也有部分屬性僅適用於DataFrame。
- df1.columns, df1.index >> df1.axes >> df1.ndim。
- df1.shape >> df1.size。
- df1.info >> df1.values。
- df1.dtypes。
- df1.at[0,'demand'] <<>> df1['demand'][0] <<>> df1.iat[0,1]。
- df1.demand <<>> df1['demand']。
- df1[1:3], df1[lambda df: df.columns[0]]。
- iloc
- df1.iloc[[0,1,2]]
- df1.iloc[0]
- df1.iloc[0,1]
- df1.iloc[:,2]
- df1.iloc[[True, False, True, True, False]]
- df1.iloc[1:3,1:3]
- loc
- df1.loc[0]
- df1.loc[[0,1]]
- df1.loc[:,['cargo', 'price']]
- df1.loc[:, lambda df: ['cargo', 'price']]
- df1.demand.loc[[2,3,4]]
- df1.loc[[True, False, True, True, False]]
- df1.loc[df1['demand'] > 100]
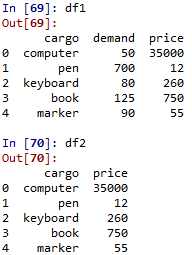
Operations
- 適用於Series的方法大都可用於DataFrame,有的需要指派方向(軸),有些僅適用於DataFrame。
- df2.index.name = 'id',df2.columns.name = 'items': index與columns的名稱。
- 改變其中的值: df2['price'] = [36000, 15, 250, 800, 50], df2['price'][0] = 36500, df2.iloc[1,1] = 20, df3['one'] = 100。
- 新增一個column或row: df2['newColumn'] = 18或 df2['newColumn'] = [36000, 15, 250, 800, 50]; df2.loc['newRow'] = 36500 或 df2.loc['newRow']=[1,2,3,4,5]。
- 改變數值型態: df1['price'] = df1['price'].astype('float')。
- 基本運算
- 若要進行df1+df2,兩者的index相同者才會相加(e.g. s2+s3),index不同處則疊加。
- 若要疊加直接使用append >> df1.append(df3)。
- df3.combine(df4, lambda s1,s2: s1 if s1.sum() < s2.sum() else s2):combine兩個DataFrame,函數須給兩參數(兩個series),然後傳回一個DataFrame。
- df5 = [df1, df4]: 疊加(與df1+df4不同)
- pd.concat([df3, df4]) or pd.concat([df3,df4], axis= 1, join_axes=[df3.index]): slightly different from [df3, df4]
- pd.merge(df3, df4, how='left', on=['one','two']):如果how='inner',需要row內容相同才會合併。如果how='outer'會疊加。
- join
- 數學運算: 取得一個column(也就是Series),再將函數應用,e,g, np.sin(df1['price']), np.sum(df1['price'])。
- 使用agg(aggregate)將函數應用於Series上: df1['price'].agg('min')或df1['price'].agg(lambda x: x*2)或df1['price'].agg(['min','max'])。
- 也可以使用apply: df1['price'].apply(lambda x: x*2),df1['price'].apply('sqrt'), df1['price'].apply(['min','max'])。
- 也可以使用transform: df1['price'].transform('sqrt')或df1['price'].transform(lambda x: np.sqrt(x))。
- 或使用pipe: df1['price'].pipe(lambda x: np.sqrt(x))或df1['price'].pipe(np.min)或df1['price'].pipe(min)。
- df1['price'].add(df2['price']), df1['price'].sub(df2['price']),df1['price'].mul(df2['price']),df1['price'].div(df2['price']): df1['price']+-*/df2['price'](subtract, multiply, divide)。使用iloc[]來取得一個row的Series來進行row向的運算。
- 整個DataFrame的計算,與上述僅針對兩個Series不同:
- 相當於每一個column都減去s內的對應值,其餘運算(+-*/)相同。
- 若是df3+df4,因為row跟col相同,所以對應元素會進行運算。
- df3.iloc[0]%13 vs. df3['one']%13。
- df3['one'].pow(df3['two']), or df7 = pd.DataFrame(np.arange(1,10).reshape(3,3))>>df7.iloc[1].pow(df7.iloc[0])。
- df3['one'].prod()(或df3['one'].product()): production of df3['one']。
- df2['rate']=[np.random.rand() for i in range(5)] >> df2['rate'].round(2): 取小數後2位四捨五入。
- df3.cummax(axis = 0) and df3.cummax(axis = 1):Return cumulative max。
- df3.cummin(axis = 0) and df3.cummin(axis = 1):Return cumulative min 。
- df3.cumprod(axis = 0 or 1): Return cumulative product。
- df3.cumsum(axis = 0 or 1): Return cumulative sum。
- df3.dot(df4.T) or df3.T.dot(df4): dot product。
- df3[df3 > 30].fillna(method = 'ffill') and df3[df3 > 30].fillna(method = 'bfill'): 往前與往後填滿NaN。See also >> df3[df3>30].fillna(0)。
- 統計相關函數:
- df1.T: 轉置矩陣,同df1.transpose()與np.transpose(df1)。
- df1.describe()。
- df1.count()。
- df1.max() & df1['price'].max()。
- df1.min() & df1['price'].min()。
- df1.mean() & df1['price'].mean()。
- df1.median() & df1['price'].median()。
- corr(other, method='pearson', min_periods=None): correlation with `other` Series, excluding missing values。df3['one'].corr(df3['two'])或df3['one'].corr(df3['two'], 'kendall')或df3['one'].corr(df4['two'])。
- df3.corrwith(df4): See also df3.corrwith(df4,axis=1)。
- cov(other, min_periods=None):covariance with Series, excluding missing values。df3['one'].cov(df3['two'])
- diff(periods=1): discrete difference of object。df3.diff()或df3['one'].diff()或df3.iloc[0].diff()或df3.T.diff()
- df3.pct_change()或df3['one'].pct_change(): 前後元素的增減比例。
- mad(axis=None, skipna=None, level=None): mean absolute deviation。df3.mad()或df3.mad(1)
- df3.std(): standard deviation。或df3['one'].std()或df3.iloc[0].std()
- df3['one'].ptp():最大跟最小值之差。
- df3.sample(3) or df3['one'].sample(3): 隨機取三個元素。
- df3.sem()或df3['one'].sem(): unbiased standard error of the mean。
- df3.sum()或df3['one'].sum()。
- df3.var()或df3['one'].var()或df3.T.var(): unbiased variance。
- 邏輯判斷: 判斷是否符合條件。
- df3 > 30: 傳回一個boolean陣列。若是df3[df3>30]則傳回符合條件(True)的DataFrame。
- df3.clip(10, 90),df3.clip(lower = 10),df3.clip(upper = 90): 將小於10的值變成10,大於90的值變成90。
- df3.isin([7, 81]), df3['one'].isin([7, 81]): 傳回一個boolean DataFrame or 陣列(值為7或81傳回True)。若是df3[df3.isin([7, 81])]則傳回符合條件(True)的DataFrame。。
- isnull(): 判斷是否為missing values(e.g. np.NaN),e.g. dfnan = df3[df3.isin([7, 81])] >> dfnan.isnull()。
- notnull(): 判斷是否不為missing values,dfnan.notnull()。
- all() & any(): Series.all(axis=0, bool_only=None, skipna=True, level=None, **kwargs),e.g.(df3<90).all()或(df3>90).any()
- duplicated(keep='first'): 判斷是否有重複。keep='first'表示判斷該元素之前是否有與其重複之元素,keep = 'last'表示判斷該元素之後是否有與其重複之元素,keep = False表示判斷該元素是否為重複元素。
- df1.eq(df2): 判斷對應元素是否相等。
- df3.ge(df4): 判斷對應元素是否大於等於。
- df3.gt(df4): 判斷對應元素是否大於。
- df3.le(df4): 判斷對應元素是否小於等於。
- df3.lt(df4): 判斷對應元素是否小於。
- df3.ne(df4): 判斷對應元素是否不等於。
- df3.idxmax(): 傳回最大值之index(df1.idxmax()傳回錯誤因為字串無法轉換成實數)。
- df3.idxmin(): 傳回最小值之index。
- df1.items() or df1.iteritems(): 傳回項目的iterable物件。
- (df1[df1 > 500])['price'].last_valid_index(): Return index for last non-NA/null value.。
- df1.where(df1>100) vs. df1.where(df1['demand']>100): where保留True,False則為NaN。df1.where(df1>100, 0) vs. df1.where(df1['demand']>100, 0)。
- df1.mask(df1>100) vs. df1.mask(df1['demand']>100): mask保留False,True則為Nan。df1.mask(df1>100, 0) vs. df1.mask(df1['demand']>100, 0)。
- df3.nunique() v.s. df3.T.nunique(): 判斷非重複的元素個數。
- df3['one'].unique(), df3.loc['c'].unique(): 傳回沒有重複元素的array。
- 選取或處理元素。
- df1.get('cargo'): 相當於df1['cargo']。
- df1.at[0,'demand']: 相當於df1['demand'][0]或df1.loc[0].at['demand']或df1['demand'].at[0]或df1.get('demand').at[0]。
- df1.get_values(): see also df1.get('cargo').get_values()。
- df1.get_dtype_counts(): 判斷各類型元素個數。
- df1['price'].compress(df1['price']>100): 等同df1.get('price')[df1.get('price')>100]。
- df3.get('one').between(50,100) & df3['one'][df3.get('one').between(50,100)]: df1['cargo'].between('book','marker', inclusive=False)不包含判斷值。也可用於字串。
- df1_copy = df1.copy(): 建立物件的copy。
- df1_copy.pop('demand'): 移除column為demand之Series。Try del df1['price']。
- truncate(before=None, after=None, axis=None, copy=True): 移除前後,e.g.df1.truncate(before=1, after=3), df3.truncate(before='one', after='two', axis = 1)。
- df1_copy.drop(1): 刪除index為1之row。Try df1.drop('price', axis = 1)
- df5.drop_duplicates('B', 'first',inplace=False) or df5.drop_duplicates('B', 'last',inplace=False): 刪除column B中重複元素之row。
- (df3[df3<80]).dropna(): 刪除missing values所在之row。
- groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs):
- df1.head(3)): 選取前三元素,預設值為5。
- df1.tail(3): 選取後三元素。
- df3.applymap(fun): 將fun應用到df3的元素。也可以使用之前提及的agg, apply, transform, pipe等方式。
- df3.nlargest(2, 'one'): 選擇'one'中前2大的值所在的row。
- df3.nsmallest(2,'one'): 選擇'one'中前2小的值所在的row。
- df3['one'].nonzero() or df3.get('one').nonzero(): 選擇值非0的index。
- df2.reindex_like(df1): 使用df1的index,df2的值。
- df2['price'].repeat(3): 重複元素3次。
- df3.replace(5,100): 將df3中的值為5的元素替換成100。
- df3.rolling(2).sum(): column中每2個連續元素之和,傳回DataFrame。df3.rolling(2, axis=1).sum()
- df3.sample(2) or df3.sample(n=2): 隨機取2個row。df3.sample(n=2, axis = 1)為取兩個column。
- df1.take([1,3]): 選取index=1,3的row,自0起算,傳回DataFrame。df1.iloc[1:4:2]可以得到相同效果,此方式適用於規律間隔之選取,take可選任意row。df1.take([0,2], axis=1)則選取column
- df1.get('demand').update(pd.Series([1,2,3,4,5])) or df1['demand'].update(pd.Series(np.random.randint(100, 1000, 5))): 更新column demand內的元素值。也可以使用df1['demand']= np.random.randint(10,1000, 5)。
- df4.get('one').unique(): 傳回column one中沒有重複元素的array。try df4.iloc[0].unique() and df4.loc['a'].unique()。
- df1.filter(items = ['demand']) or df1.filter(items = ['demand', 'price']): 僅選取某一column。
- df1.filter(regex = 'e$') or df1.filter(regex = 'e+'): 使用regex選取column。
- df1.filter(like='3', axis = 0) or df1.filter(like='pri', axis = 1): 選擇包含3或pri之row或column。
- items, regex, 與like應分開使用。
- df3.idxmax(),df3.T.idxmax() or df3.idxmax(axis=1): idxmin用法相同。
- df1.xs('cargo', axis = 1) or df1.xs(1):取得row或column。
- indexing:
- df1.columns.name = 'items'或df1.index.name = 'id':修改columns name。
- df1.add_prefix('item_')或s1.add_suffix('_item'):修改每一column的名稱。
- df1.reindex([1,3,2,0,4]):修改index的順序,若是給不同的index,內容會變成NaN。若是要重新命名index,使用df1.index = ['a','b','c','d','e']。
- df1.rename({'a':1,'b':2,'c':3,'d':4,'e':5}):可用來重新命名index。使用兩個mapper來改變row跟column的名稱,e.g. df1.rename({'a':'A'}, {'cargo':'ITEMS'})。
- df1.rename_axis({'a':1,'b':2}) or df1.rename_axis({'cargo':'items'}, axis=1): 可用來改變index或columns的名稱。
- df1.set_axis(0, [1,2,3,4,5]) and df1.set_axis(1, ['A','B','C']): 修改df1的index與column為第二個參數。
- df1.stack()與df1.unstack():將DataFrame轉換成多重index。
- df3['one'].value_counts(): 計算各元素個數。
- swapaxes(axis1, axis2[, copy]): df3.swapaxes(0,1)。See also>>df3.T
- 內插(interpolate): df1[df1 < 500].interpolate()
- 排序:
- df1['demand'].argsort()傳回index的排序(非元素值的排序)。
- df1.sort_index()根據index排序,reindex用來重排index以方便排序。
- 若使用df1.sort_index(ascending=False)>>降冪。
- 若使用df1.sort_index(ascending=False, inplace=True)>>直接排序s8(不需再指派給其他變數)。
- df1.sort_values(by='demand')根據column demand的value排序。
- 若使用df1.sort_values(by='demand', ascending=False)>>降冪。
- 若使用df1.sort_values(by='demand', ascending=False, inplace=True)>>直接排序s8(不需再指派給其他變數)。
- 資料處理傳輸
- df1.to_clipboard(): 複製到system clipboard。
- df1.to_csv('temp.csv') or df1.to_csv('temp.txt'): 寫到csv檔。pd.read_csv('temp.csv') or pd.read_csv('temp.csv', sep=',') or pd.read_csv('temp.csv', header = None) or pd.read_csv('temp.csv', names = ['id', 'info1', 'info2', 'info3'])
- df1.to_dict(): 轉為dict。
- to_html(): 。
- df1.to_excel('data1.xls', 'sheet1'): 寫到excel檔。Read from excel: pd.read_excel('data1.xls'), pd.read_excel('data1.xls', 0), pd.read_excel('data1.xls', 'sheet1')
- df1.to_json(): 轉換為JSON。
- pickle(>>import pickle): df1.to_pickle('pkframe.pkl') >> pd.read_pickle('pkframe.pkl')。
- df1['price'].to_frame() or df1.loc[1].to_frame(): Series轉換為dataframe。
- df1.to_string()。
- df1['price'].tolist() or df1.loc[1].tolist(): 傳回column(row) values的list。
- to_sql。
- cut: Can hanle the statistics of large data
- permutation: shuffle the data。
-
Time Series:以時間為軸的資料。
- 使用pd.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs)方法。
- 也可以使用pd.date_range(start='1/1/2018',end='12/31/2018', freq='M')。
- 若使用pd.date_range(start='1/1/2018',end='12/31/2018'),沒有freq,內定為日,所以會有365個週期。freq有以下常用選擇:
- B: 上班日
- D: 日
- W: 周
- M: 月底
- SM: 月中
- BM: 上班月底
- MS: 月初
- SMS: 半月
- BMS: 上班月初
- Q: quarter end
- BQ: business quarter end
- QS: quarter start
- BQS: business quarter start
- A: 年底
- BA: 上班年底
- AS: 年初
- BAS: 上班年初
- BH: 上班小時
- H: 小時
- T, min: 分鐘
- S: 秒
- L, ms: 毫秒(milliseconds)
- U, us: microseconds
- N: nanoseconds
- 上述freq也可以加上數字,例如5D, 12H(每5日, 12小時)。
- normalize為True的話會先將start跟end轉化為當日0時。
- tz為時區。
- closed初始值為None,表示start跟end兩個時間點包含在區間,可改為left(左包含)或right(右包含)。
- 若是時間並非規則的
- 使用Timestamp()來建立時間。
- 原則上Timestamp()內的參數可以為以下形式:'1/1/2018','2018/01/01', '20180101', '2018.01.01', '01.01.2018', 'Jan 1, 2018'(通常為月日,若是不合理則自動改為日月。e.g. '12.13.2018' vs. '13.12.2018')。若是只有月分,可簡化為'2018-01','2018-02'等
- asfreq: 可用來改變freq,自動內插
- 使用to_datetime建立DatetimeIndex
- 使用dt.year, dt.month, dt.day, dt.hour, dt.minute來取得個別參數。
- 使用dt[1]-dt[0]取得兩個時間之差。
- first & last (for TimeSeries): df7.first('3M'), df7.last('5M')。See also >> df7.head() & df7.tail(3)
- truncate: 去除前後。e.g. df7.truncate(before='2018-03-01', after='2018-10-01')。